--> Try it out LIVE <--
I had a "Chat with Jon York" button on my website as a prank to get people to think they were talking to me while they were really talking with an LLM. For a while my setup was a simple prompt given to gpt-4o-mini which told it to act like me and provided all of my interests, sample messages, who my friends were, and so on, but I never could quite get the chats I wanted. Everything seemed too LLM-y.
So, as my final project before leaving back to college this fall, I wanted to up my prank game by fine-tuning gpt-4.1-mini on my entire iMessage history. Here is how I did it and how it went.
Extracting my iMessages
If you are on Mac, you can use some tool like iMazing or imessage-exporter to export your entire iMessage history quickly. However, since I was on Linux, I had to work a bit harder.
Using ChatGPT's help, I installed these packages:
$ sudo apt install libimobiledevice6 ifuse idevicebackup2
And then I had to install libusbmuxd via brew since the latest package available though apt didn't support the latest iOS version. You can reference my conversation with ChatGPT if you want to see more.
After, I was able to run these commands to create a backup:
$ idevicepair pair
$ idevicebackup2 backup ~/iphone-backup
Then, you should find your message history file sms.db at ~/iphone-backup/Library/SMS/sms.db.
It took a while and a ton of disk space, and I don't know of any way to only extract the messages instead of doing an entire back up, but once you get the messages db, you can get rid of the rest of the data, unless you want to include attachments as well.
I ran this against the sms.db file to export all of my messages as CSV. It excludes group chats.
sqlite3 "sms.db" <<EOF
.headers on
.mode csv
.output messages.csv
SELECT
m.ROWID AS message_id,
m.guid AS message_guid,
datetime((CASE WHEN m.date > 2000000000 THEN m.date/1000000000 ELSE m.date END) + 978307200,'unixepoch','localtime') AS message_date,
CASE m.is_from_me WHEN 1 THEN 'sent' ELSE 'received' END AS direction,
m.is_read,
h.id AS handle,
c.display_name AS chat_name,
c.guid AS chat_guid,
m.service,
m.text,
m.associated_message_type AS reaction_type,
m.associated_message_guid AS reacted_message_guid,
a.filename AS attachment_path,
a.mime_type AS attachment_type,
a.total_bytes AS attachment_size
FROM message m
LEFT JOIN handle h ON m.handle_id = h.ROWID
LEFT JOIN chat_message_join cmj ON cmj.message_id = m.ROWID
LEFT JOIN chat c ON c.ROWID = cmj.chat_id
LEFT JOIN message_attachment_join maj ON maj.message_id = m.ROWID
LEFT JOIN attachment a ON a.ROWID = maj.attachment_id
WHERE c.ROWID IN (
SELECT c.ROWID
FROM chat c
JOIN chat_handle_join chj ON chj.chat_id = c.ROWID
GROUP BY c.ROWID
HAVING COUNT(chj.handle_id) = 2
)
ORDER BY m.date ASC;
EOF
And I got the data that I needed:
message_id,message_guid,message_date,direction,is_read,handle,chat_name,chat_guid,service,text,reaction_type,reacted_message_guid,attachment_path,attachment_type,attachment_size
86841,15FE9ADB-B45F-4FE9-8A4E-4B8042A4537D,"2025-08-24 16:23:40",sent,0,+1XXXYYYZZZZ,"",iMessage;-;+1XXXYYYZZZZ,iMessage,"Ngl i was thinking i",0,,,,
86842,2893B446-636C-4C13-A787-FADDEAC5FF71,"2025-08-24 16:23:42",sent,1,+1XXXYYYZZZZ,"",iMessage;-;+1XXXYYYZZZZ,iMessage,T,0,,,,
86843,4995DC0D-5F5E-4AE7-96EA-03F5C37AC177,"2025-08-24 16:26:01",received,1,+1XXXYYYZZZZ,"",iMessage;-;+1XXXYYYZZZZ,iMessage,"No way",0,,,,
86844,C93AA9A6-6EE1-40F1-92B4-7720ED865C2B,"2025-08-24 16:26:04",received,1,+1XXXYYYZZZZ,"",iMessage;-;+1XXXYYYZZZZ,iMessage,"You too?!",0,,,,
86845,60AADDA4-F6E8-43F5-9985-2218ACC3B7B5,"2025-08-24 16:26:57",sent,0,+1XXXYYYZZZZ,"",iMessage;-;+1XXXYYYZZZZ,iMessage,"Yes...",0,,,,
... (110k lines total) ...
Fine Tuning
I had to organize the chats into a JSONL file for training. OpenAI actually recommends starting with only ~10 very high quality examples, but I figured since I already had all of this data I might as well use it. Also, it would be very hard to encapsulate my entire personality in only 10 very high quality examples, and I wanted to capture my personality as well as I could for the best emulation.
I decided for my first attempt to just to assemble all of my messages for each contact into separate training points and chunk conversations by day so that their wouldn't be multiple conversation topics in the same thread. I got around 2,000 conversation threads, a bit low since I removed any thread which had attachments in it to simplify, and uploaded it in the OpenAI dashboard for fine tuning.
This worked somewhat well, but unfortunately a lot of my text message history is kind of boring. I think I just say "Yeah" to end conversations very often, so the bot ended up learning that and saying "Yeah" with nothing else pretty often, which wasn't fun to chat with.
My solution to this was to build out (have Claude build out) a web interface where I could manually go through and currate the data:
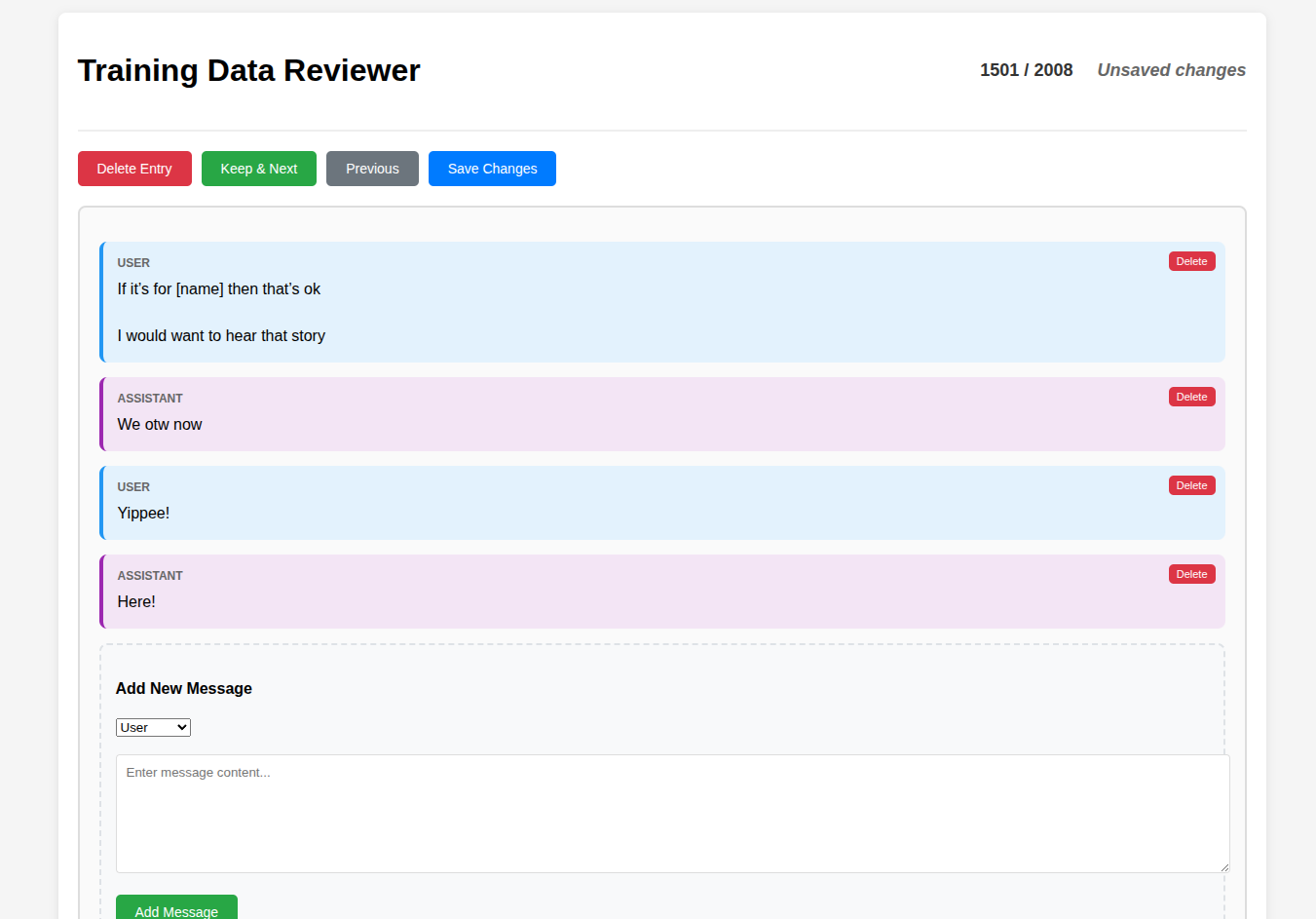
This let me edit the messages as I wanted and generally get rid of any incoherent messages, while also moderating what's going in to the LLM as to not expose any of my personal information (which, side note, I suprisingly didn't actually find to be a problem in my first attempt). The result was much better.
Prompting
Along with fine-tuning, you can actually also still add a system message to the model. I wasn't expecting it to listen to system message instructions particuarly well given that we fine-tuned it away from the methodical instruction-following, and it didn't, but it still did pretty good with some toying around.
I was able to explain that it was chatting in my website and gave it some up-to-date context about myself. The key was to add in a bunch of example chat chains in the prompt since the training data was pretty messy -- it was across many, many different contexts, people, times, etc, so I had to give it a reasonable understanding of how I wanted it to chat with people on the website by giving it a ton of examples.
End Result
Overall, I'm pretty happy with fake Jon. He definitely doesn't pass the turing test, and he definitely hallucinates, and he isn't super smart/aware, but I would say that fake Jon does mimic the tone and style of my own texting quite well. I was pretty impressed when I asked it what my greatest fear was and it told me a pretty deep, accurate answer despite that question not appearing anywhere in the training set. But, I asked it again in a separate thread and it told me "Clowns", which is a bit off, so who knows.
This was a fun project nonetheless and I'm excited for people to continuously get pranked by my AI bot.
Future Plans & Ideas
- Use an LLM to enhance the training data. I got bored and didn't work all that hard for many of the chats, and I only got through around 25% of them.
- Either manually creating or using an LLM to create a Direct Preference Optimization dataset to promote messages that sound like me. OpenAI is logging all of my chats, so I'm hoping I can just export and use those.
- Real life Black Mirror "Hang the DJ" - A dating app where people fine-tune bots on their text history and then send them out to chat with other people's bots and see if they get along.